Problem: You downloaded and tested a new LLM model from HF. You test it - everything works great for the first couple of examples. Now, you want to deploy it to a production-ready framework (triton, tfserving, torchserve, vllm, trt-llm, etc.), and the end-to-end test result seems to be different or even plain out wrong.
I will show you a specific method that I’ve been using for years for debugging neural networks of different kinds. Specifically, it helps a lot while converting models between different formats and runtimes. Let’s take, for example, +Llama-3.2-11B-Vision-Instruct+. We’ll pick TensorRT-LLM as our “production” backend that is expected to serve the requests, while testing is done using good ol’ +Huggingface+. It was all good until I reached a problem that virtually broke the of out business case: for some images, llama would incorrectly parse some of the parts of the document. Neither vLLM nor +Huggingface+ had that problem.
Let’s say it was a web page snapshot with a VQA-like question about a specific number located on the page. Two frameworks gave similar answers, notably regarding the answer to the question. HF - does, +TRT-LLM+ - does not.
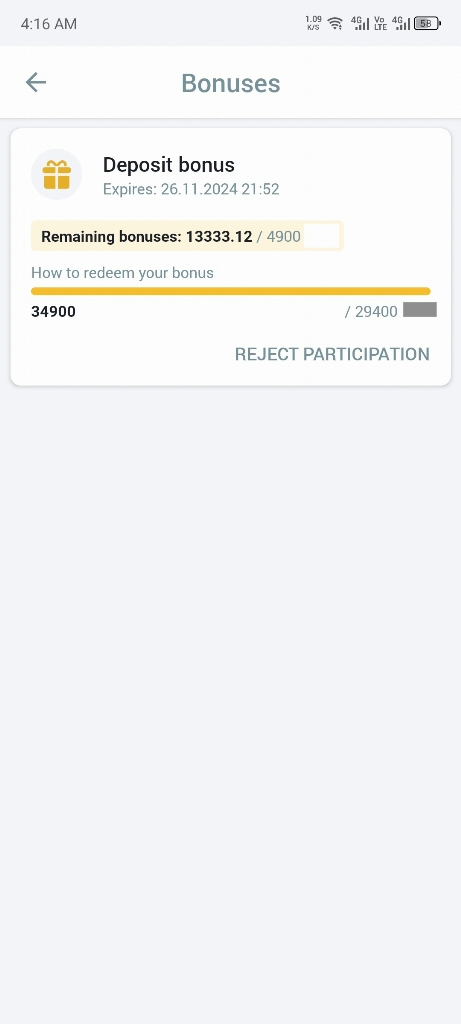
The prompt that was given to it was asking for the correct date of something that happened and was mentioned in the page, and the correct the answer should have been something like
- Huggingface:
"The date shown in the screenshot is 26.11.2024." - TRT-LLM:
"The date shown in the screenshot is November 1, 2023."
For the intended use case, it’s not enough to merely respond in a grammatically and semantically correct way; I need to get the precise answer to my question. Now that we see the differing outputs, we want to investigate the reasons. One of the possibilities here is to localize the discrepancy first. Of course, two LLM frameworks cannot be incorrect everywhere. For that, I would recommend - let’s call it - +comparative LLM surgery+. It is a universal method for all kinds of neural networks - not just LLMs. In short, it means we extract meaningful parts of intermediate layers (one - from a healthy specimen and the faulty one), and then compare them one to one.
The plan for diagnosing the LLM is as follows:
- First, we check that the tokenizer works the same way for both cases.
- Fix manually any intermediate layer. I.e., fixing manually the visual encoder part, for example. Literally extracting the layer outputs from Torch and injecting it in the TRT-LLM pipeline.
- Register debug outputs within TensorRT
- Create debugging wrapper for HF transformer blocks
- Write debugging outputs to .pt files | Write HF outputs to wherever you want them
- Compare shapes, compare distribution, and/or compute
+corrcoef+ - Compare outputs: plot the hidden state
- Compare outputs’ difference between layers (in case some of them are skipped)
- After assessing the results, pronounce the diagnosis
Today we will examine the troublesome difference of outputs between those of TRT-LLM (former FasterTransformer) and Torch (and Huggingface) of a relatively new multi-modal Llama - namely meta-llama/Llama-3.2-11B-Vision-Instruct
1 Preparing (or preparating) the TRT-LLM
Llama-11B-Vision consists of 39 transformer blocks. We want to mark the output of each transformer block and save them somewhere. TensorRT and the TRT-LLM specifically - are very optimization intensive it is done by registering the outputs first. Let’s do just that. Let’s follow this guide
It’s essential to build the model in debug mode such that it does not optimize out your outputs:
trtllm-build
--checkpoint_dir ${UNIFIED_CKPT_PATH}
--output_dir ${ENGINE_PATH}
--max_batch_size 1
--enable_debug_output # important part
--max_seq_len 2048
--max_encoder_input_len 6404 I’ll cite the manual here:
hidden_states = residual + attention_output.data
residual = hidden_states
hidden_states = self.post_layernorm(hidden_states)
hidden_states = self.mlp(hidden_states)
# Register as model output
# ------------------------------------------------------
self.register_network_output('mlp_output', hidden_states)
# ------------------------------------------------------
hidden_states = residual + hidden_statesWhat we need to do first is find forward() in the MLLaMAModel class (located in models/mllama/model.py) and register the output just after the transformer block - this will get us 39 debug outputs - one for each layer - which we would be able inspect at runtime later:
# somewhere in the forward() function
for i, (decoder_layer, past) in enumerate(
zip(self.layers, kv_cache_params.past_key_value)):
lora_layer_params = None
if lora_params is not None and lora_params.lora_ranks is not None:
lora_layer_params = lora_params.get_layer_params(i)
hidden_states = decoder_layer(
hidden_states,
encoder_output=encoder_output,
attention_mask_params=attention_mask_params,
use_cache=use_cache,
... # full parameter list is omitted
)
# here goes the important part
self.register_network_output(f"triton_debug_{i}", hidden_states[0])
# notice that hidden_states[1] is kv-cache. We don't need it for now2 Preparing the Torch model
That is the easier part. I’ll show you how to instrument or hijack the
forward method of the model. We will create a separate +util.py+ containing a +torch.nn.Module+ Wrapper class. In order to produce the corresponding forward wrapper, we need to replicate the original argument list. By the way, one pretty cool tool may come in handy when observing complicated +forward+’s. It gives us the full signature with type hints!
import inspect
sig=inspect.signature(model.language_model.forward)
print(sig)
"""
Signature (input_ids: torch.LongTensor = None, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, cross_attention_states: Optional[torch.LongTensor] = None, cross_attention_mask: Optional[torch.LongTensor] = None, full_text_row_masked_out_mask: Optional[Tuple[torch.Tensor, torch.Tensor]] = None, ...
"""This output is of particular benefit when the structure of the module is significantly complex or when looking at source code is not an option for some reason…
So the wrapper of the transformer block looks something like this:
class DebugTransformerBlock:
"""Wrapper class to add debugging to a transformer block"""
def __init__(self, block, layer_idx: int = 0):
self.block = block
self.layer_idx = layer_idx
self.debug_data = []
# Replace forward method with your version
block.forward = self.forward_with_debug # The important part Later we define:
def forward_with_debug(
self,
hidden_states,
cross_attention_mask,
...
)
outputs = self.original_forward(
hidden_states,
attention_mask=attention_mask,
cross_attention_mask=cross_attention_mask,
...
)
step_n = len(self.debug_data)
self.debug_data.append({
'step': step_n,
'layer': self.layer_idx,
'output': outputs[0].detach().cpu()#.numpy(),
})
# save tensors for further examination
torch.save(outputs, f"./torch_debug_step{step_n}_{self.layer_idx}.pt")
self._print_debug_info(self.debug_data[-1])And the actual patching is done like this:
for layer_n in layers:
if hasattr(model, 'transformer'):
first_block = model.transformer.h[layer_n]
elif hasattr(model, 'model'):
first_block = model.model.layers[layer_n]
else:
raise ValueError("Could not locate transformer blocks in model")
# Add debugging
debug_wrapper = DebugTransformerBlock(first_block, layer_idx = layer_n)3 Running the input
I used the examples/multimodal/run.py provided by the TensorRT-LLM library for testing with default settings and debug_mode turned on. In my case it didn’t work though, because the debug_mode argument did not pass correctly over to the runner itself, so I hardcoded it to True int runner.
python3 tensorrtllm_backend/tensorrt_llm/examples/multimodal/run.py
--visual_engine_dir /tmp/trt_engines/Llama-3.2-11B-Vision-Instruct/vision_encoder/
--visual_engine_name visual_encoder.engine
--llm_engine_dir /tmp/trt_engines/Llama-3.2-11B-Vision-Instruct/fp16/
--hf_model_dir /tmp/hf_models/Llama-3.2-11B-Vision-Instruct/
--input_text "Question: What date is shown in the screenshot? Answer: "
--image_path pics_test/image20.jpg
--temperature 0
--max_new_tokens 20 I assume that you followed all the official instructions and are able to run the built engine with fixed inputs with no programmatical errors (also, remember, that temperature = 0 usually equals to reproducibility and determinate outputs).
When doing a debug run TRT-LLM kindly supplies a tllm_debug directory packed with pickled tensors that we’ve registered during the previous steps. Running the prompt will produce N*M*2 files: N pairs of pickled layers with text representation for each of the M steps. Keep in mind that the dimensionality of the zeroth step will be P*dim where P is the length of prompt in tokens. 2 - stands for both .txt and .npy
4 Comparing the outputs
This is the most interesting, or rather, the one and only substantial part of the post. We will now compare the outputs of the traced tensors. I will be using the following code utilizing only +matplotlib+ and focusing only on plotting the slices of embeddings (or rather - the hidden states) - token by token. I will also print the correlation coefficient to have a crude numerical measure of the discrepancy.
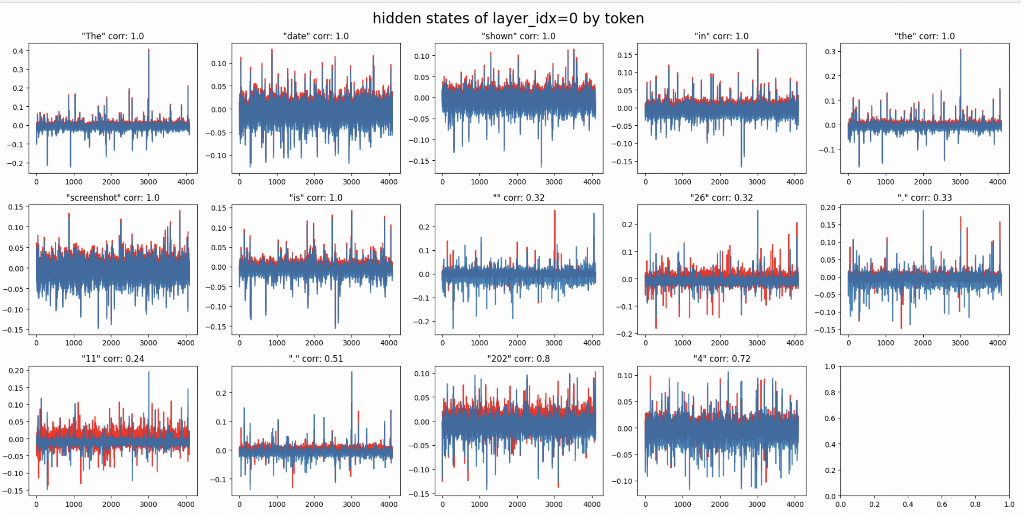
Let’s start at layer 0 and step 0.
layer_idx = 0
m=torch.load(f"/home/jovyan/torch_debug_step0_{layer_idx}.pt", weights_only=True).to(torch.float16).cpu().numpy()[0]
t = np.load(f"tensorrtllm_backend/tllm_debug/PP_0/TP_0/CP_0/transformer.triton_debug_{layer_idx}-step0.npy")
input_ids = inputs.input_ids[0]
fig, axes = plt.subplots(4, 4, figsize=(10, 10))
axes = axes.flatten()
for i, ax in enumerate(axes):
ax.set_title(f"\"{tokenizer.decode(output_ids[i]).strip()}\" corr: {np.corrcoef([t[i], m[i]])[0][1].round(2)}")
ax.plot(m[i], color='red', alpha=0.9, lw=1.5)
ax.plot(t[i]-0.01, alpha=0.9)
plt.tight_layout()
plt.show()Which gives us this nice output:
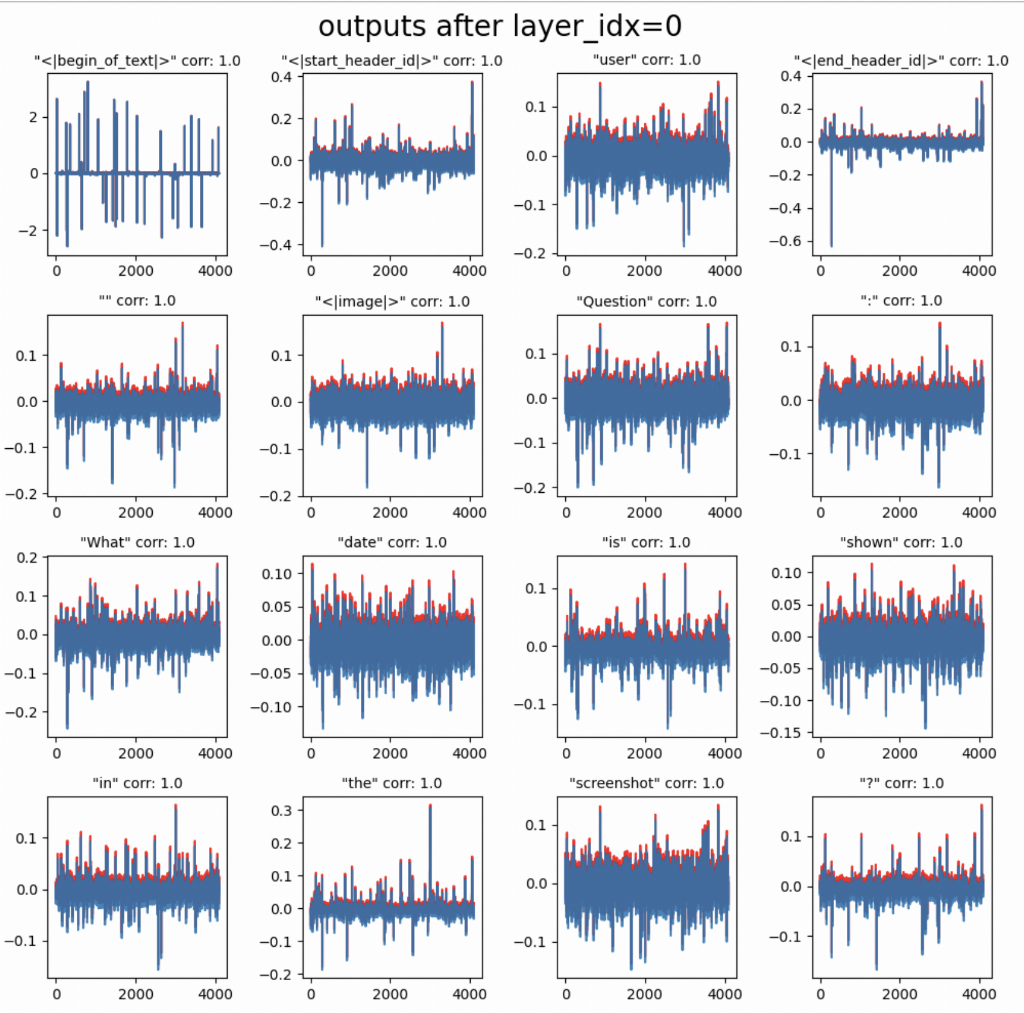
As you can see both frameworks have the same hidden states for each token. Now let’s see what happens after the first cross-attention layer_idx = 3:
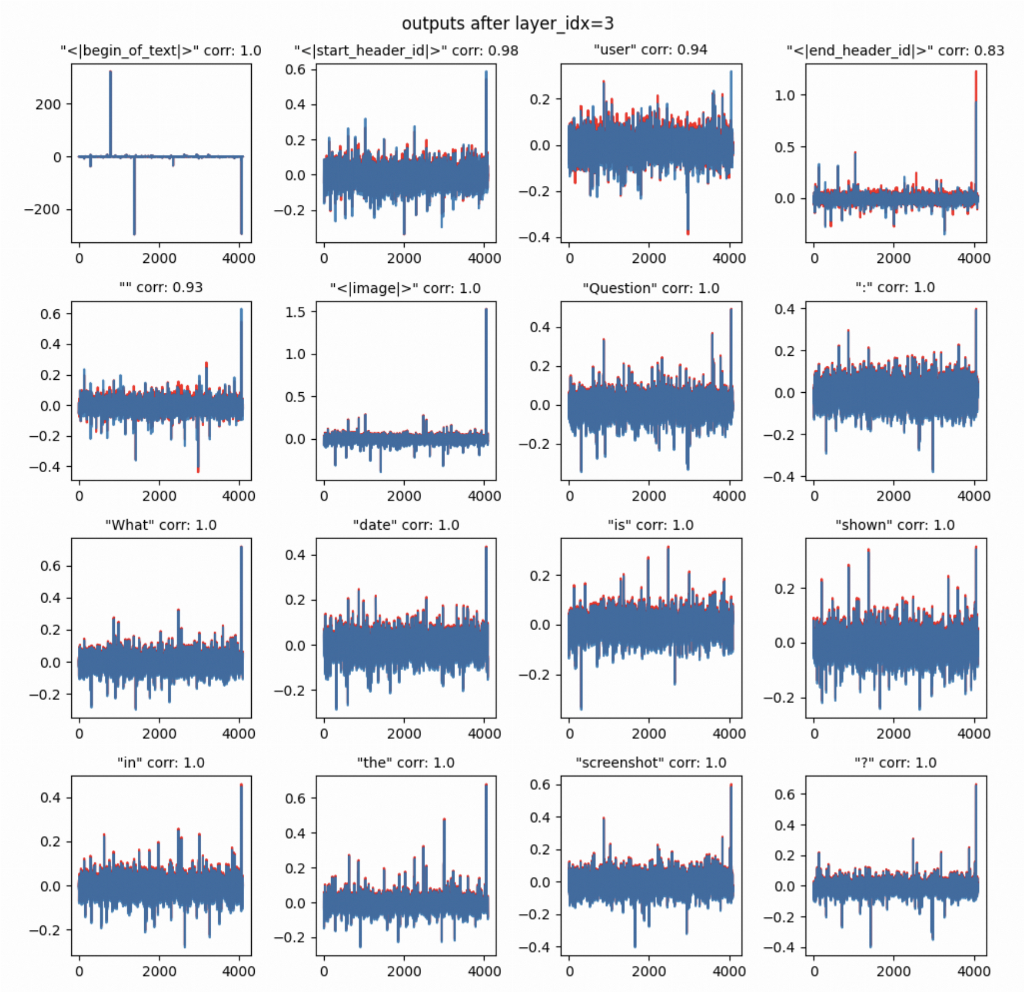
We may now visually observe the differences of hidden states that cannot be attributed to just a rescaling or varying precision (and it is not the case. Both frameworks use +bfloat16+) and may further indicate that something is going wrong here. Notably, it is indeed a case only regarding the control tokens like +user+ and +<end header_id>+. Let’s explore this further to decide whether it is only a minor numerical fluke or an actual bug. For the last layer output (layer 38):
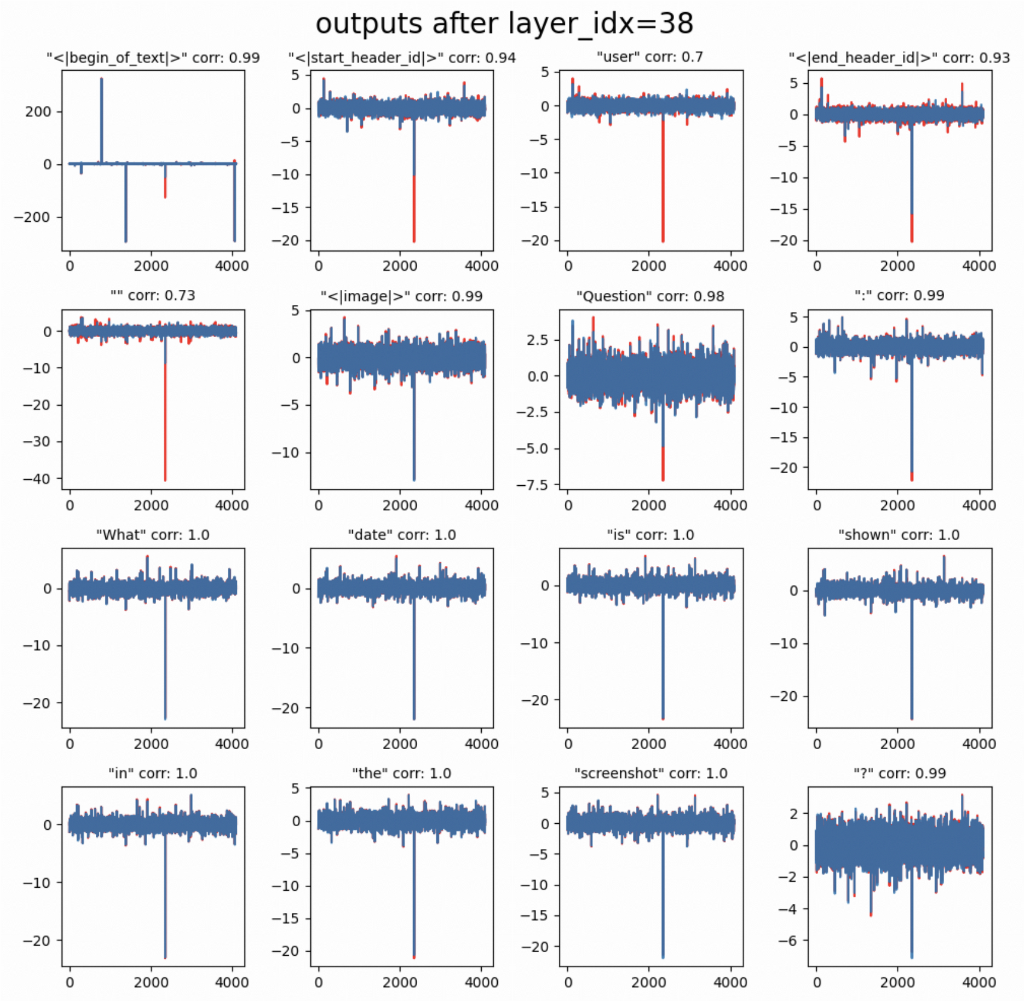
As expected, the error propagates further. Also, note the corrcoef that I use to measure discrepancy between hidden states drops to 0.7 which is the possible reason we get differing outputs in the end.
5 Going further (but not deeper)
It is also interesting to take a look at what is gonna happen from this POV when we’ll take different slices further along the generation process. I’ll slightly offset the the torch-slice to see that they are absolutely identical at Now, after the cross-attention layer (layer 3), we observe the same kind of “non-affine”-like discrepancy.
Now let’s take one more step further to finally see that our erroneous answer is not merely a decoding problem.
6 Something is wrong
Let’s make a plot that shows the delta between layers +N+ and +N-1+. And then we’ll see something peculiar. Specifically, we plot the change of the hidden state between layers 3 and 2. Layer 3 is the first of the cross-attention blocks, and weirdly, it does not affect the hidden state. It seems that our control tokens are completely masked out for all blocks in cross-attention in +TRT-LLM+ implementation. Interestingly, this is not the case for the Huggingface implementation.
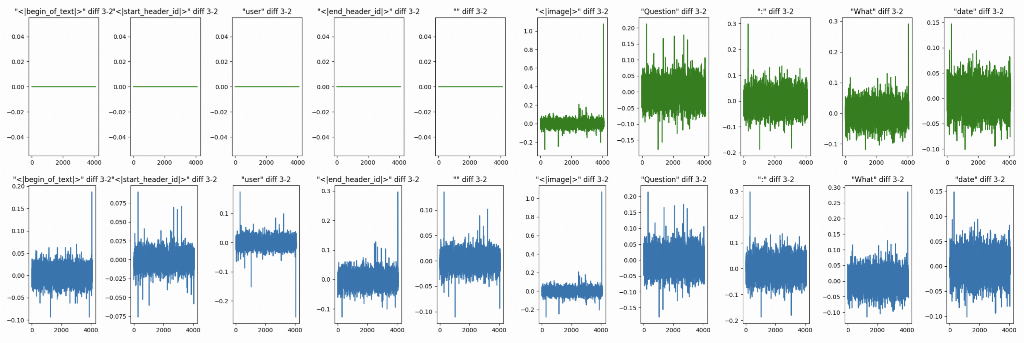
Green stands for TRT-LLM, Blue - for Torch.
What that means is that there an cross-attention mask incorrectly applied in TRT-LLM
Hereby, we conclude, that incorrect behavior has something to do with:
- cross-attention
- incorrect masking
Is it enough to cause incorrect behavior to propagate downstream until the incorrect token is generated? Possibly not, but it’s definitely worth further investigation.
7 Conclusion
What did we learn today:
- How to do some TensorRT-LLM instrumentation.
- How can models be diagnosed by implanting them all over with our probing functions?
- How to easily compare two vectors hidden states by plotting them and overlaying over each other.
- How to apply these techniques for a problem “in the wild” - an obscure malfunction in a new LLM.
Keep in mind, that all these are merely an addition to reading the code diligently.
In the next episode, we will check if Nvidia patched its implementation and also if would be able to extract attention masks and make some further observations.