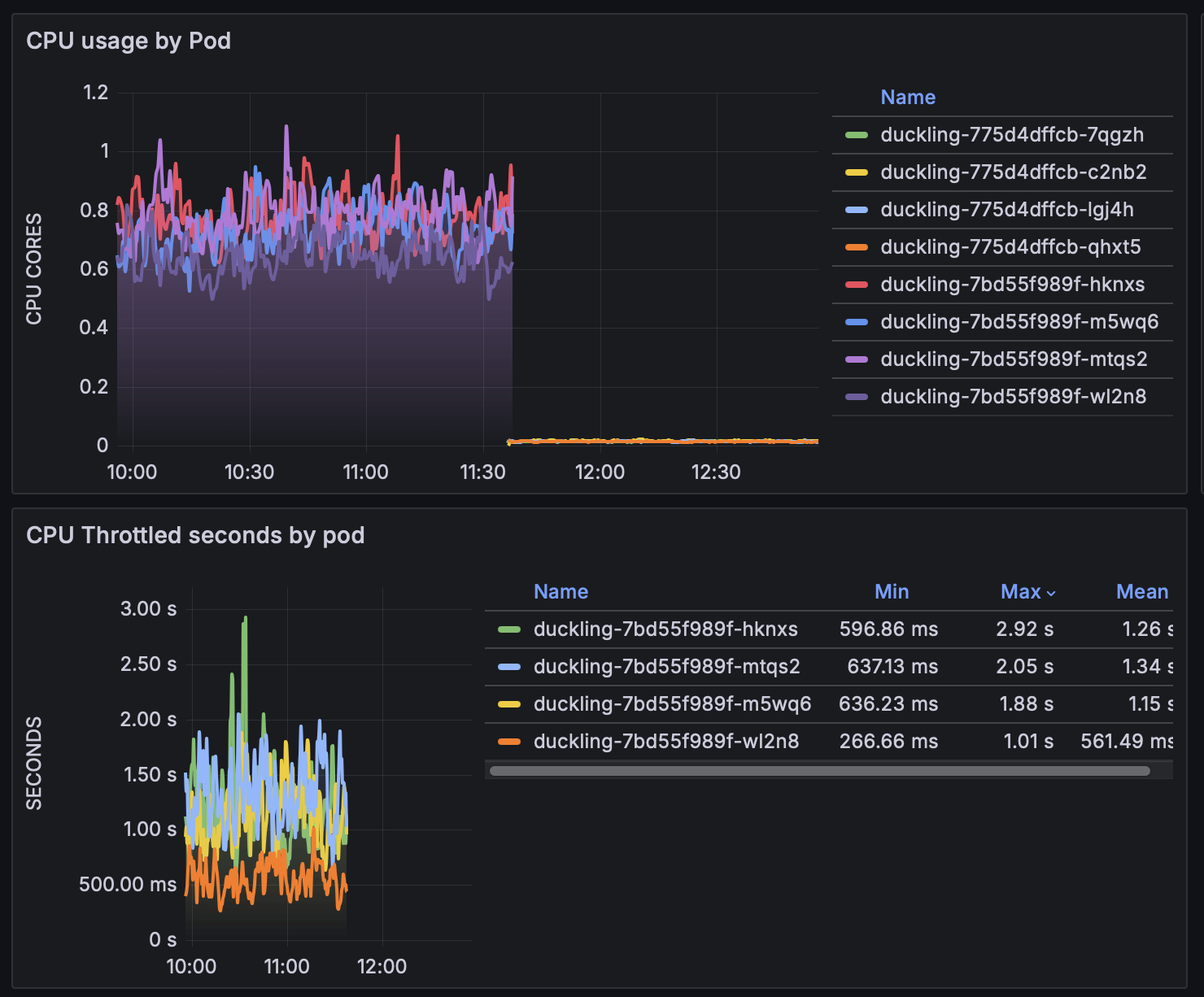
This graph shows the improvement in efficiency of a production service when redeployed with tweaked runtime parameters. Specifically, here I increased GC pre-allocation memory and the default allocation area with the -H<mem> and -A<mem> parameters, correspondingly.
By the way, this service basically is REST-wrapper around duckling. For those who don't know, duckling is a great tool for ISO-compliant parsing of different datetimes, amounts, measurements, etc, in different locales written in natural language into a structured format. For example, "Half past ten" would yield "2025-08-09T22:30:00.000-07:00". It's indispensable for workflows involving smaller LLMs (like Llama or Gemma) where imposing structural constraints would otherwise harm the accuracy of the models.